SQL 기본기
SQL을 알아야 지속가능한 데이터를 저장하는 방법을 알 수 있다
Q. 데이터는 왜 초기화되는가? (NestJS를 실행할때, 코드를 변경할때마다 서버가 재시작이 되었음. 재시작이 될 때마다 API를 통신하면서 원래 NestJS에 선언되어 있던 변수들만 그대로 사용할 수 있었음.
A. 하드웨어적인 이유 (HDD/SSD부터 RAM으로) 코드를 작성하게 되면, 코드는 SSD에 저장이 됨 → NestJS코드를 실행하게 되면 SSD에 있던 코드가 RAM으로 이동함 → RAM에 위치해있는 데이터가 실행이 되어 NestJS서버를 실행함 → RAM에 올라간 데이터는 프로그램이 재시작되면 리셋됨 → 그렇기에 실행도중 생성,변경된 변수들을 유지가 안됨 (* RAM : 데이터를 영구적 저장이 불가능) (* SSD : 데이터를 저장하면 데이터가 고장나지 않는 이상 영구적으로 저장을 해줌)
Q. 왜 RAM을 사용해야하는가?
A. RAM이 훨씬 속도가 빠르다
so, 프로그램이 종료되더라도 데이터를 유지하려면 HDD/SSD에 데이터를 작성해야 한다 이렇게 저장할 수 있는 방법중 전통적이고 흔한방법이 SQL을 사용하는 것이다
SQL(Structured Query Language)이란? SQL 은 Table로 구성이 되어있음 (*Table: 정보를 담는 구조)
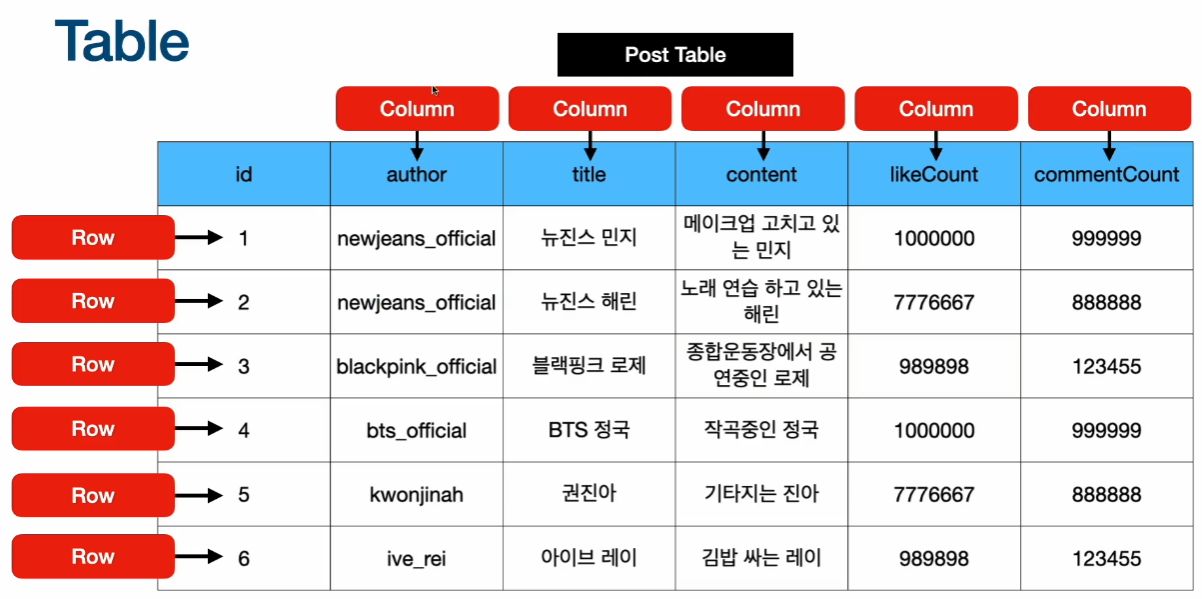
row : 실제 데이터 / column : 특성
데이터 선택(Select)
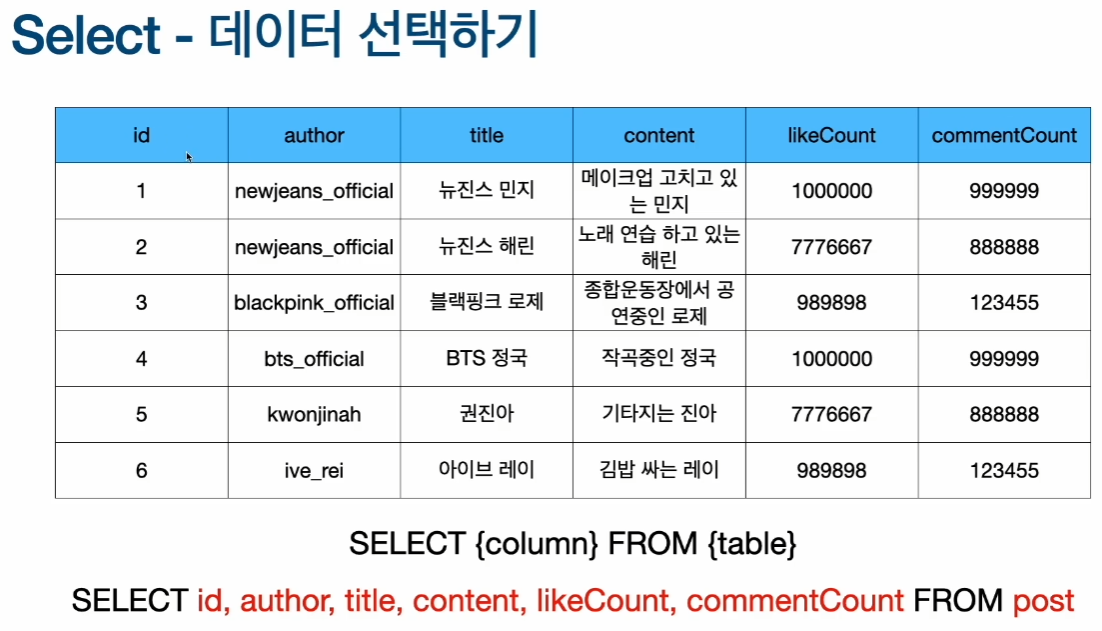
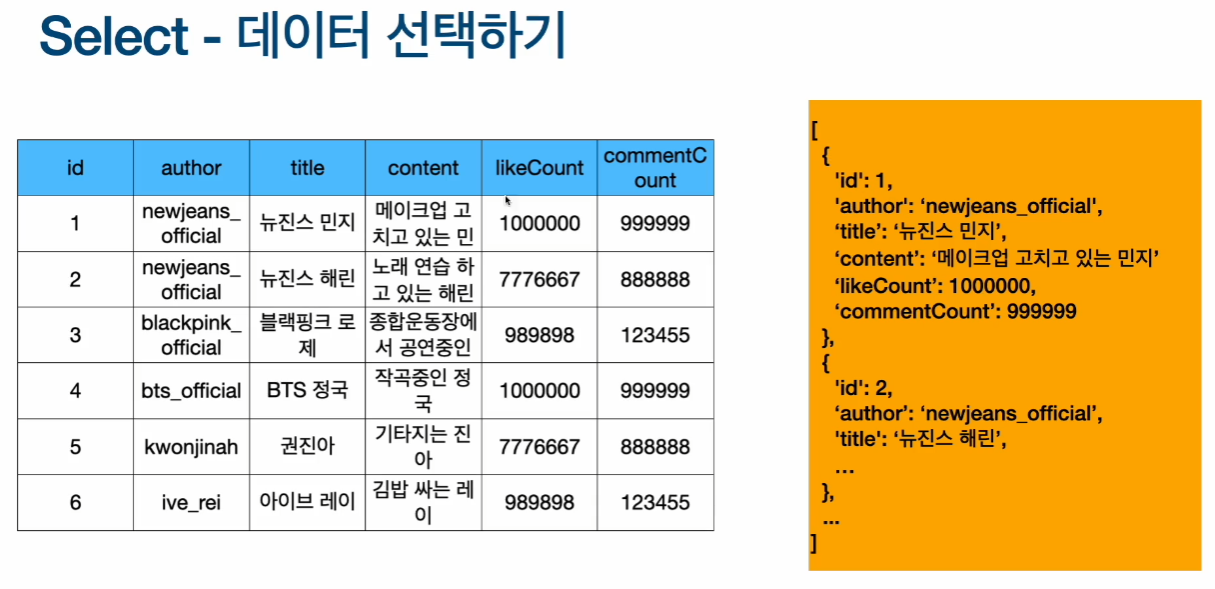
- 데이터를 선택하면 json형태로 넘어옴
- 만약 id가 3인것만 선택하고 싶으면 끝에 WHERE id=3을 넣어주면 3만 json형태로 출력됨
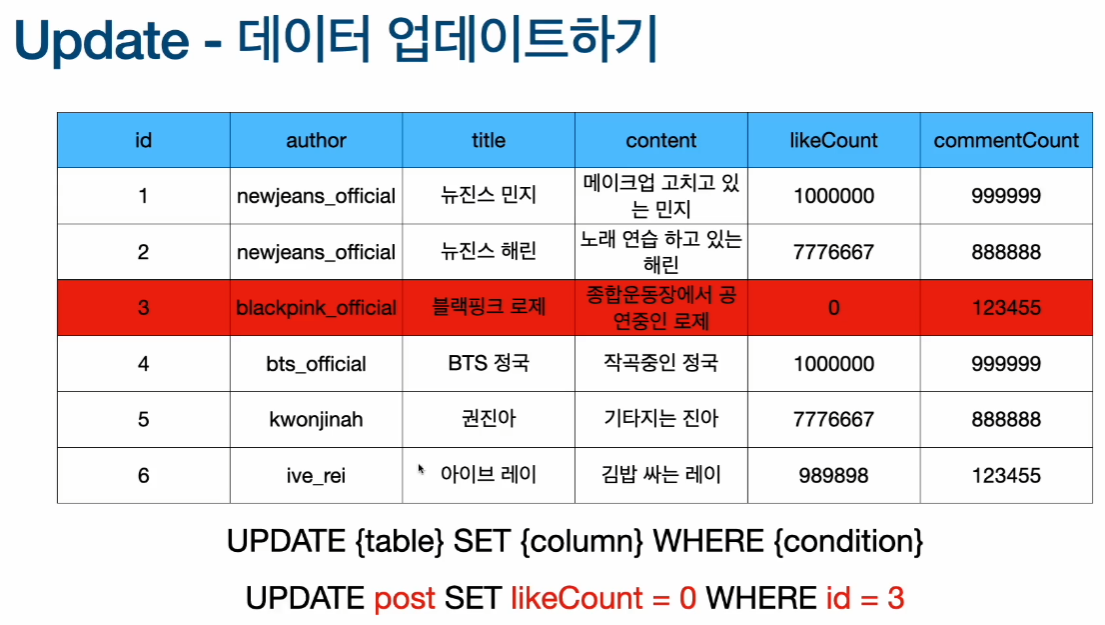
데이터 업데이트(Update)
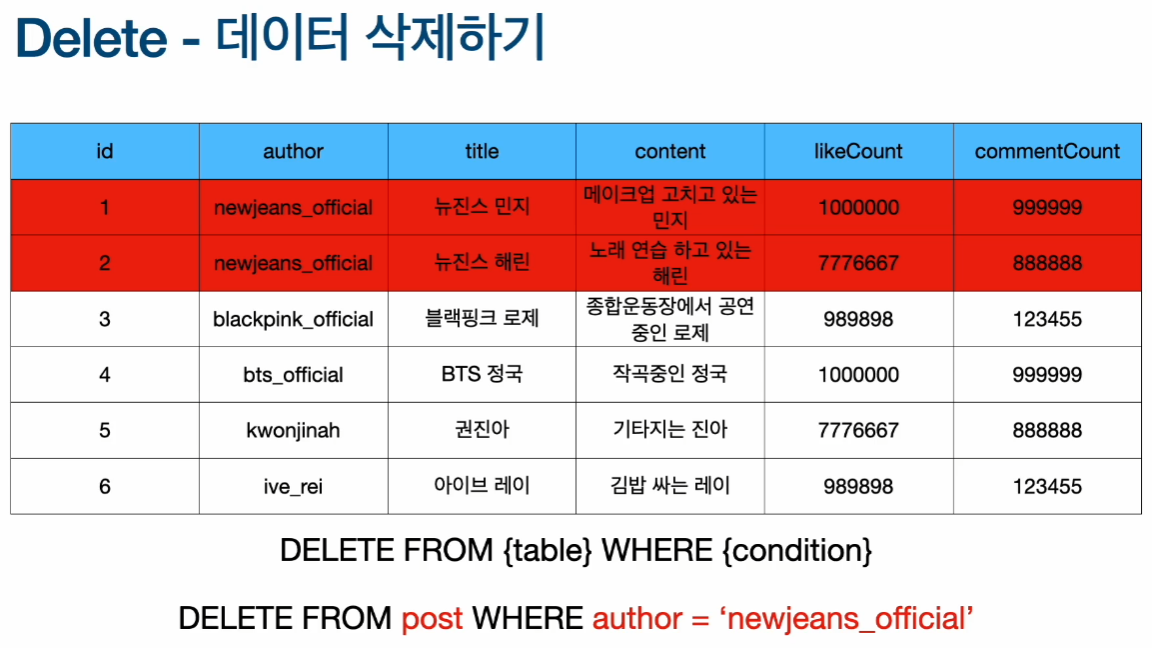
데이터 삭제 (Delete)
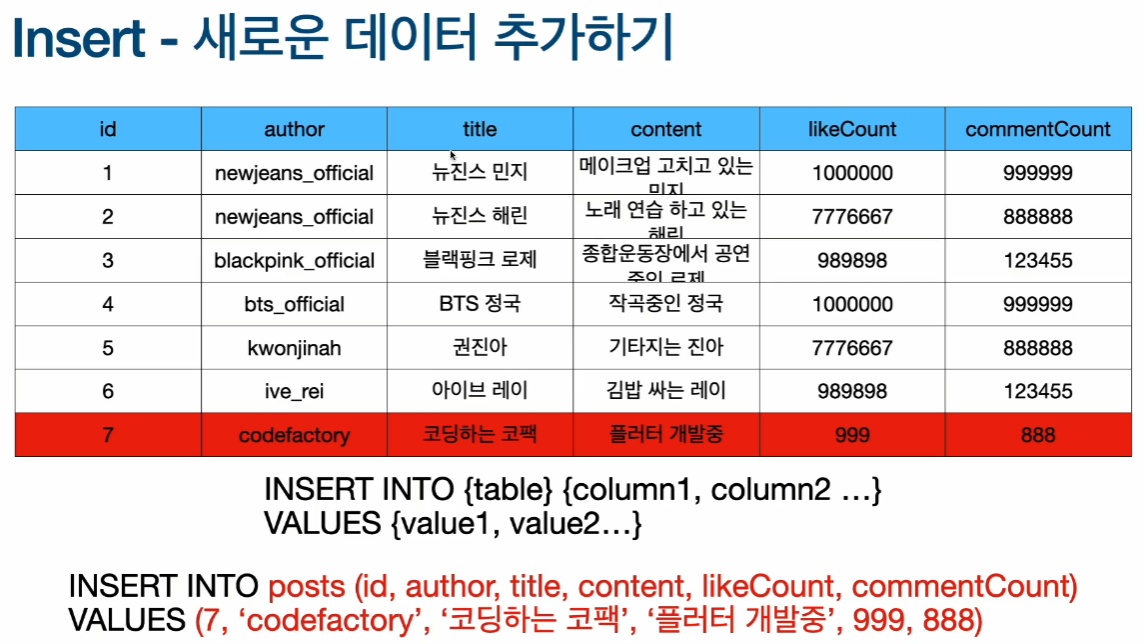
새로운 데이터 추가하기 (Insert)
TypeORM API를 사용하면 SQL문은 자동으로 생성되는 형태의 기술을 사용할 예정
Docker 이론
멀티 플랫폼(윈도우, 맥os, 리눅스) ~> 플랫폼별로 무언가 설치하거나 환경을 설정해야하는 요소들이 각각 다름
도커파일 : 순서적으로 절차를 따라 실행하면 해당 프로젝트는 어떤플랫폼이든 실행된다고 정의를 한 파일 → 도커를 실행하고 있는 플랫폼이면 윈도우,리눅스,맥os든 어디서든 항상 똑같은 환경에서 항상 똑같은 조건대로 프로그램을 실행할 수 있다는 것
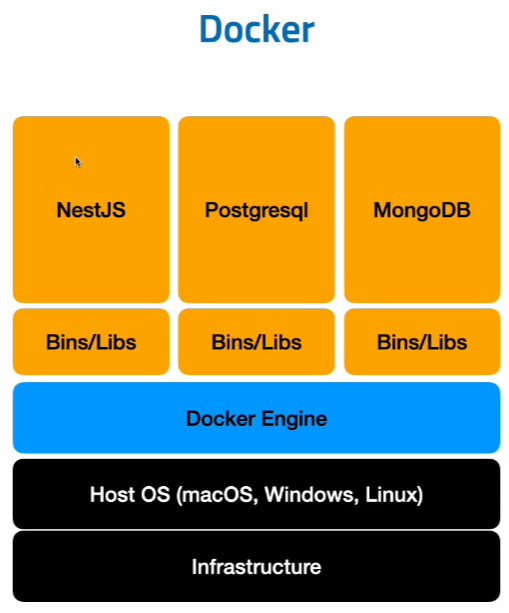
- Infrastructure : HW-cpu, 그래픽카드, 네트워크 카드
- Host OS : 3중 하나를 올림(서버면 리눅스)
- Docker Engine : 도커엔진을 host OS 위에 올리는 순간 각 플랫폼별 신경써야하는 요소들은 도커 엔지니어들만 신경쓰면 된다.
- 도커프로그램개발자가 도커엔진이 HostOS와 어떻게 연동이 될지를 써줌 (*우리는 도커파일을 사용하여 도커엔진과 연동만 시키면 됨)
- 즉, 개발자에서는 도커파일을 작성하는 방법만 알게 되면 어떤프로그램이든 도커로 컨테이너들을 자유롭게 배포할 수 있음
굉장히 쉽게 같은 조건속에서 같은 환경을 조성하여 항상 똑같은 프로그램이 똑같은 조건 속에서 실행되도록 할수 있는것이 도커다
VM 과 Docker의 차이점
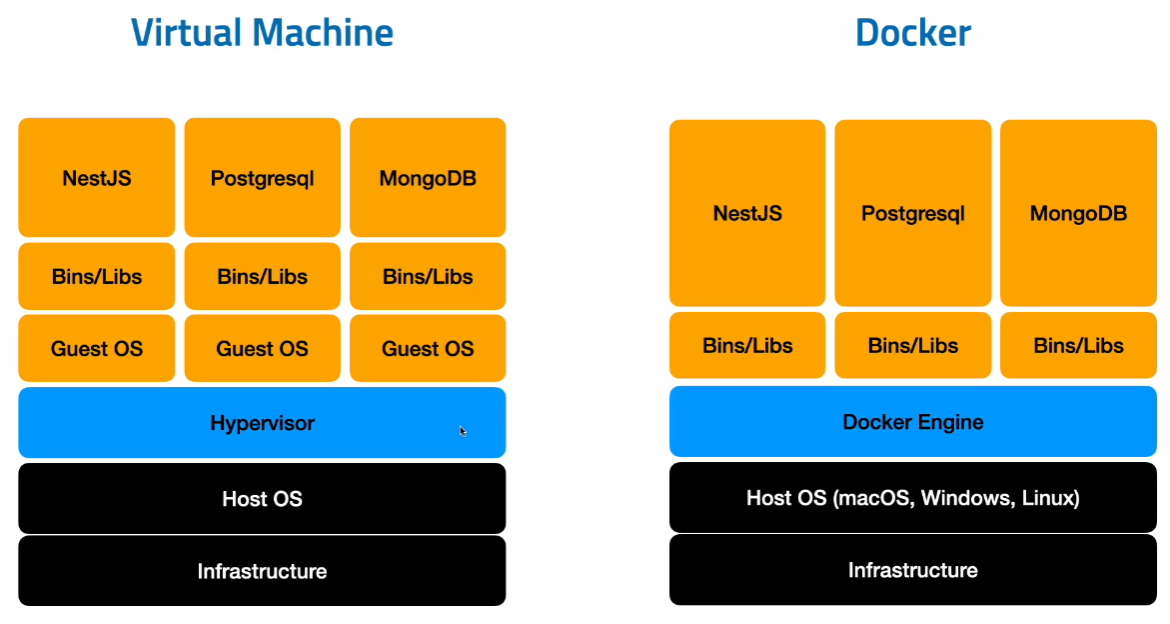
- Docker :
- 도커엔진을 통해 컨테이너들을 올림
- 특정 프로그램을 실행 할 때, 필요한 환경과 패키지들 명령어들을 하나의 컨테이너로(=도커파일이라는 컨테이너로) 묶어서 어떤 환경에서든 도커만 설치가 되어있으면 똑같은 조건속에서 해당 컨테이너를 실행할 수 있도록 해주는 것
- 네이티브하게 HostOS커널이랑 소통을 함 ~> 굉장히 빠르고 효율적
- VM : Hypervisor 후에 GuestOS가 있다 = Hypervisor를 통해서 각각 프로그램을 실행할 OS(환경)를 따로 설치해야 함 ~> 매우 무게가 무거움
Docker Compose 이론
Docker Compose는 Docker를 설치하면 기본 기능 중 하나
여러 개의 하드웨어에서 작동을 시킨다는 가정을 하고 만들어지지 않은 기술 여러 개의 컨테이너를 한번에 묶어서 관리할 수 있게 해주는 기술
K8s : 여러 기기에서 여러 컨테이너를 자유롭게 활용하는
Docker Compose 파일 작성해보기
//docker-compose.yaml
services:
postgres:
image: postgres:15
restart: always
volumes:
- ./postgres-data:/var/lib/postgresql/data
ports:
- '5432:5432'
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
services = 어떤 정보를 정의할것인지 / 실행할 서비스를 정의하는 위치
postgres = postgres라는 서비스를 정의할 것이다 / 이미지 이름과는 관계없이 본인이 직접 지어주는 서비스 이름 / postgres라는 서비스를 만들 것이다! 라는 뜻 (* 서비스이름을 이미지이름과 똑같이 지으면 인지하기 쉬워서 똑같이 지음)
image = postgres라는 서비스는 어떤 이미지를 사용할지를 정의 / 실제 찾아본 이미지 이름을 넣음 따옴표 다음에는 특정버전
restart = 실행을 할떄마다 재시작을 해라
volumes = Docker이미지 안에서 실행되었던 파일들은 Docker이미지 안에서만 존재함 → 그렇기에 Docker를 종료시키면 그 이미지 안에 존재했던 파일들이 날아갈 수가 있다. → postgresql안에다가 저장해놨던 데이터를 실제 HostOS의 volumes과 맵핑을 해줄 예정 → 프로젝트 안에 폴더를 만들어서 연결 할 예정 → 이미지가 꺼지거나 삭제되어도 관계없이 postgresql안에 있는 데이터를 유지할 수 있다
.(현재위치)/postgres-data(폴더):/(연동한다)var/lib/postgresql/data(이것과)
ports = 포트 매핑 (이미지 속에서의 포트와 HostOS에서의 포트를 매핑)
environment = 환경설정 (DB에 대한 정보를 추가로 넣어줌)
그 후 터미널에서 docker-compose up 을 치면 (* up:실행 / down:종료) 굉장히 많은 로그가 뜨면서 실행되다가 마지막에 database system is ready to accept connections 이 뜬다
이후 postgres-data폴더를 열어보면 많은 데이터들이 들어와있는것을 확인할 수 있다.
'3. Backend > NestJS' 카테고리의 다른 글
| [코드팩토리 NestJS 강의] Typeorm 사용해보기 (0) | 2024.03.14 |
|---|---|
| [코드팩토리 NestJS 강의] AppModule과 main.ts 파일 (0) | 2024.03.13 |
| [코드팩토리 NestJS 강의] Module, Provider and Inversion of Control (제어의 역전) (2) | 2024.03.12 |
| [코드팩토리 NestJS 강의] Service (서비스) (0) | 2024.03.12 |
| [코드팩토리 NestJS 강의] Query and Parameters (쿼리와 파라미터) (0) | 2024.03.12 |


